Supposed you have some data on health care spending for different individuals and you want to know which patient characteristics increase health care spending. While this seems like something any health economist could do, measuring the relationship require both knowing (i) which independent variables to include in your data analysis and (ii) their functional form. Option (i) can be determined based on previous studies and clinical experts, but even that is imperfect. Point (ii) is very difficult to decipher. Is there a data-driven way to accomplish this?
A paper by Belloni, Chernozhukov, and Hansen (2014) proposes using post-double-selection (PDS) to identify relevant controls and their functional form. Consider the case where we want to model the following:
yi = g(wi)+ ςiwhere
E(ςi|g(wi))=0The Belloni paper treats g(w) as a high-dimensional, approximately linear model where:
g(wi) = Σj=1 to P (βjxi,j+rp,i)Note that in the Belloni framework, it is possible for the number of control variables (P) be larger than the number of observations (N). How can you have more regressors than outcomes? Basically because Belloni requires the causal relationship to be approximately sparse meaning that out of the P control variables, only s of them are different from 0 where s ≪ n.
Belloni proposes identifying these s important variables using a Least Absolute Shrinkage and Selection Operator (LASSO) model from Frank and Friedman (1993) as follows:
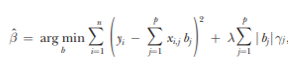
Under LASSO, coefficients are chosen to minimize the sum of the squared residuals plus a penalty term that penalizes the size of the model through the sum of absolute values of the coefficients. The term λ is the penalty level which provides the degree to which one penalizes the number of variables with non-zero (or very small) coefficients. Papers such as Belloni et al. (2012) and Belloni et al. (2016) provide some reasonable estimates for the value of λ. The gamma coefficients are the “penalty loadings” which aim to insure equivariance of coefficient estimates to rescaling of x. For instance, if one variable was schooling on a scale from 1 to 16 and another variable was income in dollars, a 1 year increase in schooling is much higher order of magnitude increase than a $1 increase in annual income. The penalty loadings aim to correct for this disparity. The authors note that:
The penalty function in the LASSO is special in that it has a kink at 0, which he penalty function in the LASSO is special in that it has a kink at 0, which results in a sparse estimator with many coeffiesults in a sparse estimator with many coefficients set exactly to zero.
One of the problems with the LASSO approach, however, is that the resulting coefficients are biased towards zero. The approach proposed by Belloni is to use post-Lasso estimation using the following two-step approach:
First, LASSO is applied to determine which variables can be dropped from the standpoint of prediction. Then, coefficients on the remaining variables are estimated via ordinary least squares regression using only the variables with nonzero first-step estimated coefficients. The Post-LASSO estimator is convenient to implement and…works as well as and often better than LASSO in terms of rates of convergence and bias.
More detail is in the paper and there are a variety of empirical examples as well. Do read the whole study.
Further, a recent paper by Kugler et al. (2021) published last month used the Belloni approach in their study to examine the impact of wage expectations on the decision to become a nurse.